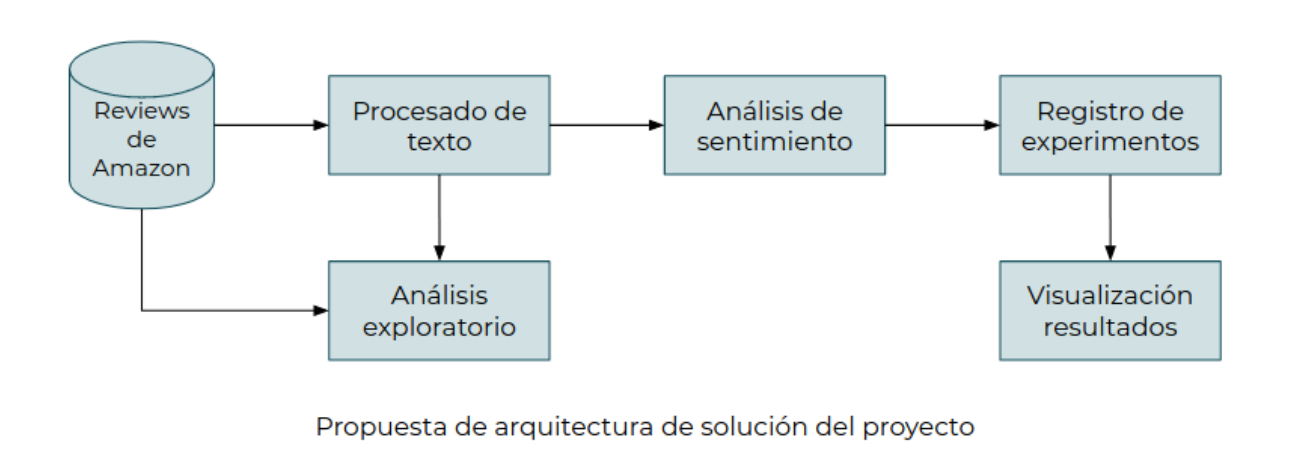
El caso consistirá en entrenar un modelo de clasificación binaria para etiquetar las reviews que escriben los usuarios de una plataforma de e-commerce en positivas o negativas en función del sentimiento expresado por el comprador.
Este documento muestra la aplicación técnica de múltiples tecnologías y frameworks para la construcción de múltiples modelos de clasificación binaria. La solución se basa aplicando la arquitectura sugerida y como insumo un dataset con reviews de video juegos de la página de Amazon.
Este documento las siguientes secciones:
import gzip
import nltk
import numpy as np
import mlflow
import pandas as pd
import shutil
import time
import plotly.graph_objects as go
import plotly.express as px
from matplotlib import pyplot as plt
from pandas_profiling import ProfileReport
from os.path import exists
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score, classification_report, confusion_matrix
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.svm import SVC
from urllib import request
from urllib.parse import urlparse
La fuente de datos proviene de productos y reviews de amazon dentro del periodo de Mayo 1996 hasta Julio 2014. Dichos reviews estan hospedados en la siguiente dirección: https://jmcauley.ucsd.edu/data/amazon/.
Para este trabajo se seleccionó de manera aleatoria el dataset de "Video games"(video juegos) categoría 5 que cuenta con 231,780 reviews. Dichos datos se encuentra en este enlance: Video Games
Dicho dataset cuenta con las siguentes columnas y una breve descripción obtenidos desde la página oficial.
Para efectos de éste trabajo y siguiendo las instrucciones del enunciado, se utilizarán las columnas reviewText y overall.
| Nombre Columna | Descripcion | Utilizar |
|---|---|---|
| reviewerID | ID of the reviewer, e.g. A2SUAM1J3GNN3B | No |
| asin | ID of the product, e.g. 0000013714 | No |
| reviewerName | name of the reviewer | No |
| vote | helpful votes of the review | No |
| style | a disctionary of the product metadata, e.g., "Format" is "Hardcover" | No |
| reviewText | text of the review | Si |
| overall | rating of the product | Si |
| summary | summary of the review | No |
| unixReviewTime | time of the review (unix time) | No |
| reviewTime | time of the review (raw) | No |
| image | images that users post after they have received the product | No |
Métodos para descarga de Archivo
Valida la existencia del archivo sino lo descarga.
def download_file(url):
out_file = 'data/reviews_Video_Games_5.json.gz'
file_exists = exists(out_file)
if not file_exists:
try:
r1 = request.urlretrieve(url=url, filename=out_file)
print(f'downloaded at {out_file}')
return 1
except Exception as e:
print(e)
return -1
else:
print('File already exists')
return 0
def parse(path):
g = gzip.open(path, 'rb')
for l in g:
yield eval(l)
def getDF(path):
i = 0
df = {}
for d in parse(path):
df[i] = d
i += 1
return pd.DataFrame.from_dict(df, orient='index')
Descargamos el archivo en folder local "/data"
download_file('http://snap.stanford.edu/data/amazon/productGraph/categoryFiles/reviews_Video_Games_5.json.gz')
File already exists
0
Cargamos los datos crudos (raw) en un dataframe
videogame_review_data_raw = getDF('data/reviews_Video_Games_5.json.gz')
Validamos la carga con 10 registros
videogame_review_data_raw.head(10)
| reviewerID | asin | reviewerName | helpful | reviewText | overall | summary | unixReviewTime | reviewTime | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | A2HD75EMZR8QLN | 0700099867 | 123 | [8, 12] | Installing the game was a struggle (because of... | 1.0 | Pay to unlock content? I don't think so. | 1341792000 | 07 9, 2012 |
| 1 | A3UR8NLLY1ZHCX | 0700099867 | Alejandro Henao "Electronic Junky" | [0, 0] | If you like rally cars get this game you will ... | 4.0 | Good rally game | 1372550400 | 06 30, 2013 |
| 2 | A1INA0F5CWW3J4 | 0700099867 | Amazon Shopper "Mr.Repsol" | [0, 0] | 1st shipment received a book instead of the ga... | 1.0 | Wrong key | 1403913600 | 06 28, 2014 |
| 3 | A1DLMTOTHQ4AST | 0700099867 | ampgreen | [7, 10] | I got this version instead of the PS3 version,... | 3.0 | awesome game, if it did not crash frequently !! | 1315958400 | 09 14, 2011 |
| 4 | A361M14PU2GUEG | 0700099867 | Angry Ryan "Ryan A. Forrest" | [2, 2] | I had Dirt 2 on Xbox 360 and it was an okay ga... | 4.0 | DIRT 3 | 1308009600 | 06 14, 2011 |
| 5 | A2UTRVO4FDCBH6 | 0700099867 | A.R.G. | [0, 0] | Overall this is a well done racing game, with ... | 4.0 | Good racing game, terrible Windows Live Requir... | 1368230400 | 05 11, 2013 |
| 6 | AN3YYDZAS3O1Y | 0700099867 | Bob | [11, 13] | Loved playing Dirt 2 and I thought the graphic... | 5.0 | A step up from Dirt 2 and that is terrific! | 1313280000 | 08 14, 2011 |
| 7 | AQTC623NCESZW | 0700099867 | Chesty Puller | [1, 4] | I can't tell you what a piece of dog**** this ... | 1.0 | Crash 3 is correct name AKA Microsoft | 1353715200 | 11 24, 2012 |
| 8 | A1QJJU33VNC4S7 | 0700099867 | D@rkFX | [0, 1] | I initially gave this one star because it was ... | 4.0 | A great game ruined by Microsoft's account man... | 1352851200 | 11 14, 2012 |
| 9 | A2JLT2WY0F2HVI | 0700099867 | D. Sweetapple | [1, 1] | I still haven't figured this one out. Did ever... | 2.0 | Couldn't get this one to work | 1391817600 | 02 8, 2014 |
Estructura natural del archivo
videogame_review_data_raw.info()
<class 'pandas.core.frame.DataFrame'> Int64Index: 231780 entries, 0 to 231779 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 reviewerID 231780 non-null object 1 asin 231780 non-null object 2 reviewerName 228967 non-null object 3 helpful 231780 non-null object 4 reviewText 231780 non-null object 5 overall 231780 non-null float64 6 summary 231780 non-null object 7 unixReviewTime 231780 non-null int64 8 reviewTime 231780 non-null object dtypes: float64(1), int64(1), object(7) memory usage: 17.7+ MB
Cantidad de Muestras
videogame_review_data_raw.count()
reviewerID 231780 asin 231780 reviewerName 228967 helpful 231780 reviewText 231780 overall 231780 summary 231780 unixReviewTime 231780 reviewTime 231780 dtype: int64
Nulos
videogame_review_data_raw.isna().sum()
reviewerID 0 asin 0 reviewerName 2813 helpful 0 reviewText 0 overall 0 summary 0 unixReviewTime 0 reviewTime 0 dtype: int64
Reporte general del dataset
El reporte generado estará adjunto a este documento.
def generate_profile_report(data, title):
profile_report = ProfileReport(data, minimal=True, title=title)
profile_report.to_file(title)
profile_report.to_notebook_iframe()
generate_profile_report(data=videogame_review_data_raw, title="Video game Dataset Raw")
Summarize dataset: 100%|██████████| 18/18 [00:03<00:00, 5.38it/s, Completed] Generate report structure: 100%|██████████| 1/1 [00:02<00:00, 2.26s/it] Render HTML: 100%|██████████| 1/1 [00:00<00:00, 8.51it/s] C:\Users\squal\anaconda3\envs\modulo_6\lib\site-packages\pandas_profiling\profile_report.py:261: UserWarning: Extension not supported. For now we assume .html was intended. To remove this warning, please use .html or .json. Export report to file: 100%|██████████| 1/1 [00:00<00:00, 251.97it/s]
Distribución de Categorías
Siendo la columna "Overall" categórica generamos una distribución porcentual, basado en una escala de 1 a 5.
labels = ['5.0 Overall','4.0 Overall','3.0 Overall','2.0 Overall','1.0 Overall']
values = videogame_review_data_raw.overall.value_counts(normalize=True)
fig = go.Figure(data=[go.Pie(labels=labels, values=values)])
fig.update_traces(textposition='inside', textinfo='percent+label')
fig.update_layout(
title='Distribución de Categorías',
width=600,
height=600,
paper_bgcolor="LightSteelBlue",
)
fig.show(renderer='notebook')
Histogramas de columna: Overall
Podemos observar la distribución visualmente presentada
df = px.data.tips()
fig = px.histogram(videogame_review_data_raw, x="overall")
fig.show(renderer='notebook')
Consideraciones:
Seguidamente se procede a un trabajo de procesado de datos para crear un dataset con alta capacidad predictiva utilizando:
Duplicados: Obtenemos las muestras duplicadas en la columna de "reviewText".
duplicated_reviews=videogame_review_data_raw[videogame_review_data_raw.duplicated(['reviewText','overall'], keep=False)]
print(f'Reviews duplicados: {len(duplicated_reviews), len(videogame_review_data_raw)}')
Reviews duplicados: (126, 231780)
Duplicados: Procedemos a borrar las muestras y observamos la reducción de muestras.
videogame_review_data_raw.drop_duplicates(subset=['reviewText','overall'], inplace=True)
print(f'Duplicated reviews: {len(duplicated_reviews), len(videogame_review_data_raw)}')
Duplicated reviews: (126, 231694)
Creamos un nuevo dataset con los tipos de datos y columnas correspondientes
videogame_review_data = pd.DataFrame({'review_text': pd.Series(dtype='str'),
'sentiment': pd.Series(dtype='int')})
videogame_review_data["review_text"] = videogame_review_data_raw["reviewText"].astype("string")
videogame_review_data["sentiment"] = videogame_review_data_raw["overall"].astype("int")
videogame_review_data.dtypes
review_text string sentiment int32 dtype: object
Validmos datos en el nuevo dataset
videogame_review_data.head(5)
| review_text | sentiment | |
|---|---|---|
| 0 | Installing the game was a struggle (because of... | 1 |
| 1 | If you like rally cars get this game you will ... | 4 |
| 2 | 1st shipment received a book instead of the ga... | 1 |
| 3 | I got this version instead of the PS3 version,... | 3 |
| 4 | I had Dirt 2 on Xbox 360 and it was an okay ga... | 4 |
Eliminamos las muestras con un valor de 3
videogame_review_data=videogame_review_data[videogame_review_data['sentiment'] != 3]
print(f"Total de registros: {len(videogame_review_data)}")
Total de registros: 203420
Balanceamos las muestras, aplicando una técnica de Random Undersampling Manual limitando el número de registros basado en el conteo de las categorías 1 y 2 y reduciendo el número de las categorías 4 y 5.
Obtenemos distribución de las columnas
print(videogame_review_data['sentiment'].value_counts())
cat_5_count, cat_4_count, cat_2_count, cat_1_count = videogame_review_data['sentiment'].value_counts()
5 120120 4 54789 1 14848 2 13663 Name: sentiment, dtype: int64
Obtenemos las muestras correspondientes a cada categoría
cat_1_data = videogame_review_data[videogame_review_data['sentiment'] == 1]
cat_2_data = videogame_review_data[videogame_review_data['sentiment'] == 2]
cat_4_data = videogame_review_data[videogame_review_data['sentiment'] == 4]
cat_5_data = videogame_review_data[videogame_review_data['sentiment'] == 5]
Creamos un nuevo dataset balanceado, utilizando muestreo y un límite inferior de la distribución (muestras de categoría 1)
videogame_review_balanced_data = pd.concat([cat_1_data.sample(cat_1_count, replace=True),cat_2_data.sample(cat_2_count, replace=True),cat_4_data.sample(cat_1_count, replace=True),cat_5_data.sample(cat_1_count, replace=True)])
videogame_review_balanced_data.shape
(55837, 2)
Definimos método para agregar etiqueta si el review es "negativa" o "positiva"
def label_sentiment(row):
if int(row['sentiment']) < 3:
return 'neg'
else:
return 'pos'
Aplicamos la nueva columna "sentiment_label"
videogame_review_balanced_data['sentiment_label'] = videogame_review_balanced_data.apply(lambda row: label_sentiment(row), axis=1)
videogame_review_balanced_data.head()
| review_text | sentiment | sentiment_label | |
|---|---|---|---|
| 138127 | This game looks like a driving game, but it is... | 1 | neg |
| 169555 | It's a cool idea of playing 4 games from previ... | 1 | neg |
| 109323 | I will never buy a game with invasive, crippli... | 1 | neg |
| 64521 | The item pictured on Amazon is not the item yo... | 1 | neg |
| 187417 | So apparently I wasted my money on this game, ... | 1 | neg |
Separamos en conjunto de train y test
x_train, x_test, y_train, y_test = train_test_split(
videogame_review_balanced_data['review_text'],
videogame_review_balanced_data['sentiment_label'],
train_size=0.80,
test_size=0.20,
random_state=42,
shuffle=True,
stratify=videogame_review_balanced_data['sentiment_label']
)
videogame_review_balanced_data['sentiment_label']
138127 neg
169555 neg
109323 neg
64521 neg
187417 neg
...
114435 pos
96196 pos
59329 pos
10912 pos
30011 pos
Name: sentiment_label, Length: 55837, dtype: object def train_vectorizer(max_features=2500, data=None):
cv = TfidfVectorizer(
max_df=0.95, # Elimina el 5% de los tokens más comunes
min_df=5, # No tiene en cuenta aquellos tokens que aparezcan menos de 5 veces
max_features=max_features, # Máximo tokens en el vocabulario
strip_accents='ascii', # Elimina acentos durante la normalización
analyzer = 'word',
lowercase=True, #convertimos a minusculas
stop_words='english', #aplicamos lista de stop_words
ngram_range=(2, 3) # Identificará y utilizará como features bigramas y trigramas
)
cv.fit(data)
return cv
Creamos multiples vectorizers con diferente número de Máximo de Tokens(Max_features)
Seteando dichos valores en: 2500 / 10000 / 50000. Utilizando el mismo dataset balanceado.
vectorizer_small = train_vectorizer(max_features=2500,data=x_train)
vectorizer_medium = train_vectorizer(max_features=10000,data=x_train)
vectorizer_large = train_vectorizer(max_features=50000,data=x_train)
Podemos ver algunas de las características (bigramas y trigramas en este caso) que hemos extraído.
Validamos tamaño y Ngrams del dataset - Small
print(list(vectorizer_small.vocabulary_.items())[:20])
print(list(vectorizer_small.idf_)[:20])
print(len(vectorizer_small.vocabulary_))
[('minutes game', 1599), ('game games', 710), ('going game', 1048), ('game just', 743), ('touch screen', 2293), ('don care', 389), ('rated game', 1927), ('avoid game', 105), ('30 40', 24), ('good game', 1059), ('game want', 930), ('games just', 986), ('just trying', 1318), ('great games', 1136), ('games like', 988), ('final fantasy', 531), ('fantasy series', 502), ('right away', 2017), ('game given', 715), ('things like', 2232)]
[6.696422120249909, 6.772583481215473, 7.207247744015899, 7.218421044614025, 6.234786740674689, 5.917097243448911, 7.062666515204792, 6.772583481215473, 7.1531805227456235, 6.256018960780464, 6.9534672232398, 7.122089935675592, 7.207247744015899, 7.0723284261165285, 6.936372789880499, 6.308894712828412, 7.185268837297124, 7.229720599867958, 6.970858965951669, 7.122089935675592]
2500
Validamos tamaño y Ngrams del dataset - Medium
print(list(vectorizer_medium.vocabulary_.items())[:20])
print(list(vectorizer_medium.idf_)[:20])
print(len(vectorizer_medium.vocabulary_))
[('minutes game', 6186), ('game games', 2947), ('tries hard', 9164), ('going game', 3961), ('game just', 3057), ('star fox', 8454), ('touch screen', 9141), ('control stick', 1219), ('don care', 1764), ('rated game', 7570), ('just stupid', 5050), ('avoid game', 411), ('game coming', 2739), ('30 40', 72), ('40 game', 112), ('game systems', 3464), ('actually makes', 234), ('makes good', 6020), ('good game', 4024), ('game want', 3538)]
[8.488181589477964, 7.755813695764737, 6.696422120249909, 7.795034408918018, 6.772583481215473, 7.207247744015899, 7.389569300809854, 7.646614403799745, 7.969387796062796, 7.218421044614025, 8.15170935285675, 8.241321511546438, 6.234786740674689, 7.945857298652602, 8.09613950170194, 5.917097243448911, 7.062666515204792, 6.772583481215473, 7.1531805227456235, 7.350348587656573]
10000
Validamos tamaño y Ngrams del dataset - Large
print(list(vectorizer_large.vocabulary_.items())[:20])
print(list(vectorizer_large.idf_)[:20])
print(len(vectorizer_large.vocabulary_))
[('minutes game', 29711), ('game games', 15262), ('tries hard', 45385), ('idea supposed', 22645), ('going game', 18883), ('game just', 15595), ('star fox', 41979), ('touch screen', 45249), ('control stick', 7319), ('stick don', 42279), ('don care', 9898), ('rated game', 37100), ('just stupid', 24368), ('avoid game', 2262), ('game coming', 14693), ('games 30', 17443), ('30 40', 372), ('40 game', 578), ('game systems', 16807), ('saying games', 39745)]
[9.309162141547795, 8.448960876324684, 8.488181589477964, 9.404472321352118, 9.222150764558164, 9.142108056884627, 9.404472321352118, 9.068000084730906, 9.404472321352118, 9.222150764558164, 9.404472321352118, 8.571563198417014, 7.755813695764737, 6.696422120249909, 9.309162141547795, 9.404472321352118, 9.309162141547795, 8.711325140792173, 7.795034408918018, 8.529003583998218]
50000
Transformamos nuestros datos en distintos datasets basados en el tamaño de la tokenización a utilizar en el entrenamiento.
x_train_small_transformed = vectorizer_small.transform(x_train)
x_test_small_transformed = vectorizer_small.transform(x_test)
x_train_medium_transformed = vectorizer_medium.transform(x_train)
x_test_medium_transformed = vectorizer_medium.transform(x_test)
x_train_large_transformed = vectorizer_large.transform(x_train)
x_test_large_transformed = vectorizer_large.transform(x_test)
Al estar en un problema de clasificación binaria, aplicamos múltiples algoritmos que sirven para éste lograr la clasificación de sentimiento:
Para éste proposito se crearon métodos parametrizables para cada uno de los algoritmos y sus modelos, que nos permite ejecutar múltiples veces manteniendo un ambiente de pruebas consistente y para cada ejecución registramos dicha información en MLFlow.
Se crearon múltiples datasets creados basados en el tamaño del vocabulario: Small, Medium, Large, con el hiperparámetro _maxfeatures. Los datasets se utilizarán para entrenar modelos y evaluarlos para obtener diferentes métricas y podemos evaluar el rendimiento en general.
Definición de clase de registro de experimentos
A utilizar en cada ejecución para mantener los resultados en memoria a utilizar en la visualización.
class experiment_model_log:
model=None
name=None
classification_report=None
def __init__(self, model, name, classification_report):
self.model = model
self.name = name
self.classification_report = classification_report
Definimos una función para entrenar un modelo con Logistic Regression
Parametrizable con la intención de probar con diferentes sets de entrenamientos. Dicha ejecución se registra en MLFLOW con los hiperparámetros, métricas y modelo utilizado.
def train_logistic_regression_model(x_train, x_test, y_train, y_test, max_iter=1000, c_param=1, solver='lbfgs',run_name=''):
with mlflow.start_run(run_name=run_name):
#Definición de modelo con algoritmo
model = LogisticRegression(C=c_param, solver=solver, max_iter=max_iter)
#Entrenamiento del modelo
model.fit(x_train, y_train)
#Obtenemos predicciones
#train_predict = model.predict(x_train)
test_predict = model.predict(x_test)
#Obtenemos métricas
print(f"Test accuracy: {accuracy_score(y_test, test_predict)}")
classification_report_model=classification_report(y_test, test_predict,output_dict=True)
#Registro de Parametros en MLFlow
mlflow.log_param("C", c_param)
mlflow.log_param("max_iter", max_iter)
mlflow.log_param("solver", solver)
#Registro de Metricas en MLFlow
mlflow.log_metric("Accuracy", classification_report_model.get('accuracy'))
mlflow.log_metric("Precision", classification_report_model.get('macro avg').get('precision'))
mlflow.log_metric("Recall", classification_report_model.get('macro avg').get('recall'))
mlflow.log_metric("f-1 score", classification_report_model.get('macro avg').get('f1-score'))
mlflow.log_metric("model id", 1)
tracking_url_type_store = urlparse(mlflow.get_tracking_uri()).scheme
# Registro del modelo en MLFlow
if tracking_url_type_store != "file":
mlflow.sklearn.log_model(model, "model", registered_model_name="Videogame_logistic_regression")
else:
mlflow.sklearn.log_model(model, "model")
return experiment_model_log(model=model,name=run_name,classification_report=classification_report_model)
Ejecución: Logistic Regression con dataset transformado con un número de tokens: Small
obj=train_logistic_regression_model(x_train_small_transformed,x_test_small_transformed,y_train,y_test,run_name='Logistic Regression - Small')
experiment_model_list = [obj]
Test accuracy: 0.7662070200573066
Ejecución: Logistic Regression con dataset transformado con un número de tokens: Medium
experiment_model_list.append(train_logistic_regression_model(x_train_medium_transformed,x_test_medium_transformed,y_train,y_test, max_iter=5000,run_name='Logistic Regression - Medium'))
Test accuracy: 0.8249462750716332
Ejecución: Logistic Regression con dataset transformado con un número de tokens: Large
experiment_model_list.append(train_logistic_regression_model(x_train_large_transformed,x_test_large_transformed,y_train,y_test, max_iter=5000,run_name='Logistic Regression - Large'))
Test accuracy: 0.8604047277936963
Definimos una función para entrenar un modelo con C-Support Vector Classification(SVC)
Parametrizable con la intención de probar con diferentes sets de entrenamientos. Dicha ejecución se registra en MLFLOW con los hiperparámetros, métricas y modelo utilizado.
def train_SVC_model(x_train, x_test, y_train, y_test, kernel='linear', run_name=''):
with mlflow.start_run(run_name=run_name):
#Definición de modelo con algoritmo
model = SVC(kernel=kernel)
#Entrenamiento del modelo
model.fit(x_train, y_train)
#Obtenemos predicciones
#train_predict = model.predict(x_train)
test_predict = model.predict(x_test)
#Obtenemos métricas
print(f"Test accuracy: {accuracy_score(y_test, test_predict)}")
classification_report_model=classification_report(y_test, test_predict,output_dict=True)
#Registro de Parametros en MLFlow
mlflow.log_param("kernel", kernel)
#Registro de Metricas en MLFlow
mlflow.log_metric("Accuracy", classification_report_model.get('accuracy'))
mlflow.log_metric("Precision", classification_report_model.get('macro avg').get('precision'))
mlflow.log_metric("Recall", classification_report_model.get('macro avg').get('recall'))
mlflow.log_metric("f-1 score", classification_report_model.get('macro avg').get('f1-score'))
mlflow.log_metric("model id", 2)
tracking_url_type_store = urlparse(mlflow.get_tracking_uri()).scheme
# Registro del modelo en MLFlow
if tracking_url_type_store != "file":
mlflow.sklearn.log_model(model, "model", registered_model_name="Videogame_SVC")
else:
mlflow.sklearn.log_model(model, "model")
return experiment_model_log(model=model,name=run_name,classification_report=classification_report_model)
Ejecución: SVC con dataset transformado con un número de tokens: Small
experiment_model_list.append(train_SVC_model(x_train_small_transformed,x_test_small_transformed,y_train,y_test,run_name='SVC - Small'))
Test accuracy: 0.7635207736389685
Ejecución: SVC con dataset transformado con un número de tokens: Medium
experiment_model_list.append(train_SVC_model(x_train_medium_transformed,x_test_medium_transformed,y_train,y_test,run_name='SVC - Medium'))
Test accuracy: 0.825304441260745
Ejecución: SVC con dataset transformado con un número de tokens: Large
experiment_model_list.append(train_SVC_model(x_train_large_transformed,x_test_large_transformed,y_train,y_test,run_name='SVC - Large'))
Test accuracy: 0.8660458452722063
Es una variación del k-fold en que retorna pliegues(secciones) stratificados, en cada set contiene aproximadamente el mismo porcentage de cada clase target del set completo, sobre un randomforest.
def train_random_forest_model(x_train, x_test, y_train, y_test,n_estimators=100, max_depth=None, run_name=''):
with mlflow.start_run(run_name=run_name):
#Definición de modelo con algoritmo
model = RandomForestClassifier(n_estimators=n_estimators,max_depth=max_depth)
#Entrenamiento del modelo
model.fit(x_train, y_train)
#Obtenemos predicciones
#train_predict = model.predict(x_train)
test_predict = model.predict(x_test)
#Obtenemos métricas
print(f"Test accuracy: {accuracy_score(y_test, test_predict)}")
classification_report_model=classification_report(y_test, test_predict,output_dict=True)
#Registro de Parametros en MLFlow
mlflow.log_param("n_estimators", n_estimators)
mlflow.log_param("max_depth", max_depth)
#Registro de Metricas en MLFlow
mlflow.log_metric("Accuracy", classification_report_model.get('accuracy'))
mlflow.log_metric("Precision", classification_report_model.get('macro avg').get('precision'))
mlflow.log_metric("Recall", classification_report_model.get('macro avg').get('recall'))
mlflow.log_metric("f-1 score", classification_report_model.get('macro avg').get('f1-score'))
mlflow.log_metric("model id", 3)
tracking_url_type_store = urlparse(mlflow.get_tracking_uri()).scheme
# Registro del modelo en MLFlow
if tracking_url_type_store != "file":
mlflow.sklearn.log_model(model, "model", registered_model_name="Videogame_random_forest")
else:
mlflow.sklearn.log_model(model, "model")
return experiment_model_log(model=model,name=run_name,classification_report=classification_report_model)
Ejecución: Random Forest con dataset transformado con un número de tokens: Small
experiment_model_list.append(train_random_forest_model(x_train_small_transformed,x_test_small_transformed,y_train,y_test,n_estimators=500,run_name='Random Forest - Small'))
Test accuracy: 0.8250358166189111
Ejecución: Random Forest con dataset transformado con un número de tokens: Medium
experiment_model_list.append(train_random_forest_model(x_train_medium_transformed,x_test_medium_transformed,y_train,y_test,n_estimators=500,run_name='Random Forest - Medium'))
Test accuracy: 0.8504656160458453
Ejecución: Random Forest con dataset transformado con un número de tokens: Large
experiment_model_list.append(train_random_forest_model(x_train_large_transformed,x_test_large_transformed,y_train,y_test,n_estimators=500,run_name='Random Forest - Large'))
Test accuracy: 0.8640759312320917
A continuación se presentan los registros de las distintas evaluaciones anteriormente ejecutados:
# Obtención de registro de pruebas
runs = mlflow.search_runs(experiment_ids=0)
runs_clean=runs
#Columnas que contiene dataframe
#print(runs_clean.columns)
#se filtran registros que se hayan terminado
runs_clean = runs_clean[runs_clean.iloc[:,2] == "FINISHED"]
# se filtran solo las columnas que interesa visualizar
runs_clean = runs_clean.iloc[:,[0,6,7,8,9,10,19]]
# Se obtienen dimensiones de dataframe
#print(runs_clean.shape)
#Mostramos resultados
runs_clean.head(10)
| run_id | metrics.Precision | metrics.f-1 score | metrics.Accuracy | metrics.Recall | metrics.model id | tags.mlflow.runName | |
|---|---|---|---|---|---|---|---|
| 0 | 5c2905a2d5ce49619e6d583e4f3e64c4 | 0.864022 | 0.864010 | 0.864076 | 0.863999 | 3.0 | Random Forest - Large |
| 1 | fdd1c35d0ffa4f9aa77449cfa9b9981e | 0.850423 | 0.850383 | 0.850466 | 0.850352 | 3.0 | Random Forest - Medium |
| 2 | b3816a54eb524c79baf7398e02c4e0ca | 0.824949 | 0.824969 | 0.825036 | 0.824995 | 3.0 | Random Forest - Small |
| 3 | 5ba79e719c524918b3febf002ec1452c | 0.866110 | 0.865943 | 0.866046 | 0.865848 | 2.0 | SVC - Large |
| 4 | 47ad4eca8d3646228c7818015a4f1fdb | 0.825268 | 0.825277 | 0.825304 | 0.825410 | 2.0 | SVC - Medium |
| 5 | e86d0e0e077f499883d41797b80f622f | 0.763906 | 0.763096 | 0.763521 | 0.762965 | 2.0 | SVC - Small |
| 6 | b432ae9de16a4bdc940f9f41e2955ad4 | 0.860564 | 0.860271 | 0.860405 | 0.860137 | 1.0 | Logistic Regression - Large |
| 7 | 7b9419f4a67e490fa4b43b9db2473a00 | 0.825141 | 0.824749 | 0.824946 | 0.824605 | 1.0 | Logistic Regression - Medium |
| 8 | f694101147b144cb859bcef5bcfb2654 | 0.766516 | 0.765825 | 0.766207 | 0.765694 | 1.0 | Logistic Regression - Small |
| 10 | bebd67430e594db2ac99af3b8e8da148 | 0.864862 | 0.864575 | 0.864703 | 0.864441 | 1.0 | Logistic Regression - Large |
Obtenemos los mejores resultados para cada una de las métricas de las ejecuciones registradas en MLFLOW:
Se muestran por cada métrica, el mejor resultado:
#se obtiene indice de registro con mayor f1 score
index_f1score_max = np.argmax(runs_clean.iloc[:,1])
#se obtiene indice de registro con mayor accuracy
index_acc_max = np.argmax(runs_clean.iloc[:,2])
#se obtiene indice de registro con mayor recall
index_recall_max = np.argmax(runs_clean.iloc[:,3])
#se obtiene indice de registro con mayor precision
index_precision_max = np.argmax(runs_clean.iloc[:,4])
#se obtiene los registros con mejor desempeño para cada métrica y su model correspondiente
print('F1 Score Max - Run ID:',runs_clean.iloc[index_f1score_max,0],', Model: ',runs_clean.iloc[index_f1score_max,6],', Value:',runs_clean.iloc[index_f1score_max,2])
print('Accuracy Max - Run ID:',runs_clean.iloc[index_acc_max,0],', Model:',runs_clean.iloc[index_acc_max,6],', Value:',runs_clean.iloc[index_acc_max,2])
print('Recall Max - Run ID:',runs_clean.iloc[index_recall_max,0],', Model:',runs_clean.iloc[index_recall_max,6],', Value:',runs_clean.iloc[index_recall_max,2])
print('Precision Max - Run ID:',runs_clean.iloc[index_precision_max,0],', Model:',runs_clean.iloc[index_precision_max,6],', Value:',runs_clean.iloc[index_precision_max,2])
F1 Score Max - Run ID: 5ba79e719c524918b3febf002ec1452c , Model: SVC - Large , Value: 0.865942554025767 Accuracy Max - Run ID: 5ba79e719c524918b3febf002ec1452c , Model: SVC - Large , Value: 0.865942554025767 Recall Max - Run ID: 5ba79e719c524918b3febf002ec1452c , Model: SVC - Large , Value: 0.865942554025767 Precision Max - Run ID: 5ba79e719c524918b3febf002ec1452c , Model: SVC - Large , Value: 0.865942554025767
def metrics_bar_graph(experiments=None):
key_macro = 'macro avg'
metricas=['Accuracy', 'Precision', 'Recall', 'f1-Score']
fig_data = dict({'data':[{}]})
#Iteracion en cada uno de los experimentos
for experimento in experiments:
data = dict({
'type': 'bar',
'name': str(experimento.name),
'x': metricas,
'y': [ experimento.classification_report.get(metricas[0].lower()),
experimento.classification_report.get(key_macro).get(metricas[1].lower()),
experimento.classification_report.get(key_macro).get(metricas[2].lower()),
experimento.classification_report.get(key_macro).get(metricas[3].lower())]})
fig_data['data'].append(data)
fig = go.Figure(data=fig_data)
# Change the bar mode
fig.update_layout(barmode='group')
fig.update_traces(texttemplate='%{y:.3}')
fig.update_yaxes(title_text="Resultados", range=[0,1], titlefont=dict(size=30)) #tickvals=[0, 0.2, 0.725, 0.750, 0.8,1]
fig.update_xaxes(title_text="Metricas", titlefont=dict(size=30))
fig.show(renderer='notebook')
def metrics_line_graph(vectorize='Small' ,experiments=None):
metricas=['Accuracy', 'Precision', 'Recall', 'f1-Score']
key_macro = 'macro avg'
fig_data = dict({'data':[{}]})
vec1, vec2, vec3 = 0,3,5
if(vectorize.lower() == 'small'):
vec1, vec2, vec3 = 0,3,6
elif(vectorize.lower() == 'medium'):
vec1, vec2, vec3 = 1,4,7
elif(vectorize.lower() == 'large'):
vec1, vec2, vec3 = 2,5,8
data = dict({
'name': metricas[0],
'x': [ str(experiments[vec1].name),
str(experiments[vec2].name),
str(experiments[vec3].name)],
'y': [ experiments[vec1].classification_report.get(metricas[0].lower()),
experiments[vec2].classification_report.get(metricas[0].lower()),
experiments[vec3].classification_report.get(metricas[0].lower())]})
fig_data['data'].append(data)
for i in range(1, 4):
data = dict({
'name': metricas[i],
'x': [ str(experiments[vec1].name),
str(experiments[vec2].name),
str(experiments[vec3].name)],
'y': [ experiments[vec1].classification_report.get(key_macro).get(metricas[i].lower()),
experiments[vec2].classification_report.get(key_macro).get(metricas[i].lower()),
experiments[vec3].classification_report.get(key_macro).get(metricas[i].lower())]})
fig_data['data'].append(data)
fig = go.Figure(data=fig_data)
# Change the bar mode
fig.update_layout(barmode='group', title=vectorize + ' Vectorizer')
fig.update_traces(texttemplate='%{y}')
fig.update_yaxes(title_text="Resultados", range=[0,1], titlefont=dict(size=30), autorange=True)
fig.update_xaxes(titlefont=dict(size=30), autorange=True)
fig.show(renderer='notebook')
En el siguiente grafico podemos observar el resultado agrupado por cada una de las métricas ['Accuracy', 'Precision', 'Recall', 'f1-Score'] de los nueve experimentos realizados anteriormente. Cada color de barra representa a un modelo de entrenamiento distinto.
En total se visualizan los resultados de nueve modelos entrenados:
metrics_bar_graph(experiment_model_list)
En el siguiente grafico podemos observar el resultado de las métricas ['Accuracy', 'Precision', 'Recall', 'f1-Score'] por cada uno de los modelos entrenados y el vectorizer utilizado.
En este caso se visualiza 3 gráficos distintos donde se comparan las metricas obtenidas de los 3 modelos usados anterioirmente ['Logistic Regression', 'SVG', 'Random Forest'] tomando como base el vectorizer utilizado ['Small', 'Medium', 'Large'].
metrics_line_graph(vectorize='Small', experiments=experiment_model_list)
metrics_line_graph(vectorize='Medium', experiments=experiment_model_list)
metrics_line_graph(vectorize='Large', experiments=experiment_model_list)